«Что нам стоит дом построить? Нарисуем — будем жить!»

История создания Витрины референсной модели Rubytech — от идеи до реализации
Классическое начало, или как данным Референсной модели стало тесно в ExcelЭта история развивалась по классическому сценарию: бизнес-пользователи (в нашем случае — команда аналитиков Rubytech) организовали сбор и обработку данных в удобном и понятном инструменте всех времен и народов, а именно — в Microsoft Excel.

|
Рис 1. Референсная модель 1.0 — «аналоговый вариант» на базе Microsoft Excel
Подход, на первый взгляд, правильный, поскольку Excel в умелых руках уже давно перестал быть редактором таблиц и может легко использоваться как база данных (БД), «слой бизнес-логики», инструмент визуализации и построения дашбордов и т.д. Однако когда дело доходит до публикации и предоставления доступа к данным «извне», пользователи Excel могут столкнуться с серьёзными функциональными и техническими ограничениями. Так было и в нашем случае. После двух лет развития, референсная модель Rubytech перестала быть «файлом» с перечнем продуктов импортонезависимого ИТ-ландшафта и эволюционировала в «ядро» сбора, анализа и оценки данных по таким продуктам. Но и этим возможности референсной модели не ограничились: данные, содержащиеся в ней, стало возможно легко адаптировать под контекст и задачи различных заказчиков.
Со временем стало понятно, что расширение круга пользователей модели поможет обеспечить знание актуального состояния рынка ИТ-продуктов для решения тактических задач крупных корпоративных клиентов; поддержку стратегических инициатив и программ по импортозамещению; значительно обогатить данные за счёт вовлечения в процесс их сбора и обработки производителей и ИТ-партнёров. Так мы поняли, что компании необходимо решение, способное обеспечить различным группам и категориям пользователей «клиентоцентричный опыт» — удобный сбор, обработку и дальнейшее использование данных об ИТ-продуктах, доступных на российском рынке.
Важно было обеспечить не просто регулярное обновления таких данных, но и гибкость организации пользовательского доступа к ним, а также возможность публикации обновлений[1] референсной модели по мере их появления.
Так появилась концепция Витрины референсной модели Rubytech.
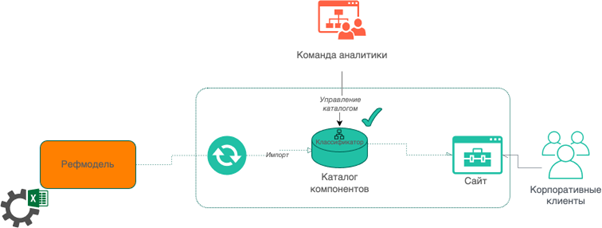
|
Рис 2. Концепция Витрины референсной модели — «цифровой вариант»
С самого начала нам показалось важным выделить отдельное хранилище с возможностью гибкой настройки модели данных (желательно — без привлечения разработчиков) в соответствии с текущими требованиями референсной модели, а также с учетом планов ее развития. Изначально в качестве технологической основы мы решили рассмотреть, популярные сегодня low/no-code ИТ-решения. Чуть позже мы пришли к выводу, что закупка, установка, настройка и лицензирование — всё это может замедлить процесс. Да и, скорее всего, по итогам мы получим избыточный функционал, который вряд ли когда-то сможем использовать: всё-таки, класс подобных решений в основном нацелен на глубокую интеграцию с корпоративным ландшафтом (сквозная аутентификация, доступ к корпоративному почтовому сервису, создание порталов). В то время как Витрина нам нужна для организации открытого публичного доступа к данным референсной модели. К тому же, хотелось получить «хорошо работающий прототип» в минимальные сроки и провалидировать все наши гипотезы по развитию Витрины.
Всё же, от самой концепции low-code мы не отказались. Так в качестве технологического ядра для реализации прототипа был выбран Headless CMS.
Headless подход: как не потерять голову от возможностей современных технологических решений
Headless CMS, информационная архитектура — звучит логично и красиво, но как же всё это реализовать? На самом деле, данный тип систем довольно распространен, и сегодня существует большой выбор не только платных вендорских, но и open source решений.
Для себя мы выбрали Strapi CMS (open source): это решение уже «из коробки» умеет много нужного и полезного. При необходимости можно встраивать в него расширения, используя сторонние или собственные плагины (NodeJS).
Из базовых возможностей нам понадобились:
1. Консоль управления (она же «админка») — идёт в комплекте поставки и имеет возможность кастомизации пользовательского интерфейса.
2. Поддержка различных баз данных в качестве основы — в нашем случае это PostgreSQL, но может быть MySQL, MariaDB и даже SQLite (но для локальной разработки).
3. Предоставление API (REST) для доступа к контенту. Помимо этого, легко расширить API сервером GraphQL, установив плагин.
4. Специфичные для CMS, но вполне релевантные для нас функции — поддержка сценариев публикации (когда управление жизненным циклом контента проходит несколько стадий), поддержка работы с медиафайлами, интернационализация и прочее.
Отдельно стоит упомянуть о модели безопасности Strapi CMS: она поддерживает не только ролевую модель предоставления прав доступа к сущностям, но и возможность настройки гибкой безопасности на уровне отдельных атрибутов (пользователям определённых ролей можно запретить просматривать/редактировать конкретные атрибуты сущности.)
Опять же, все это можно реализовать традиционным способом «на Java», но наша цель была другой — минимум кода, максимум функционала, и всё это в короткие сроки.

|

|
Рис 3. Примеры скриншотов консоли управления данными Витрины («админка»)
Так появился важный компонент — каталог с возможностью управления данными через веб-интерфейс.
***
Вернёмся к референсной модели. Как я уже рассказал вам в самом начале статьи, в качестве исходного инструмента для её создания использовался Excel. Это значит, что сама модель данных близка к реляционной (колонки таблицы, по сути, представляют собой набор атрибутов).
Поэтому при использовании Headless-подхода наша первая задача сводилась к тому чтобы унифицировать эти атрибуты и реализовать таблицу в виде модели данных Strapi CMS.

|
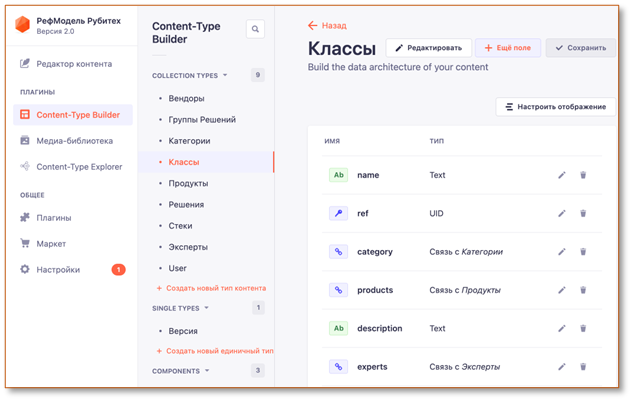
|
Рис 4. Примеры скриншотов модуля управления моделью данных
Важно еще раз отметить, в режиме low-code[2] мы получили полнофункциональный редактор данных для референсной модели с возможностью управлять ключевыми сущностями (класс, продукт, производитель и т.д.) через конфигурацию и пользовательский интерфейс.
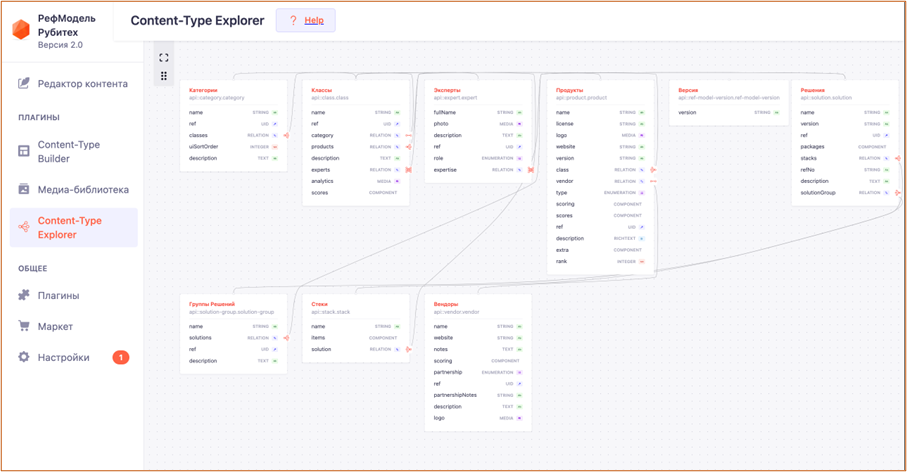 |
Рис 5. Визуализация модели данных ключевых сущностей
Теперь, когда сама модель данных построена, встал вопрос миграции текущих данных из Excel в Strapi CMS. Этот прием мы выполнили в два этапа:
-
Нормализация, трансформация и выгрузка данных в .csv при помощи OpenRefine.
-
Загрузка данных посредством API через Postman.
Все еще ноль строчек кода, но данные уже «переехали» из таблиц в полноценную доменную модель и обрели семантическую форму.
Переходим к публикации: или как «прикрутить голову» к Headless CMS
Как я уже рассказывал ранее, основным преимуществом headless-подхода к управлению контентом (информацией) является разделение самого контента и его представления. Тут мы снова обратимся к индустриальному опыту, где уже разработан целый ряд решений для визуализации и «материализации» контента, который будет транслироваться конечному пользователю. Мы остановили свой выбор на генераторе статических сайтов GatbyJS. Стоит сказать, что описание самого инструмента (равно как и споры на тему «почему не Next/Astra/…») заслуживает отдельной статьи. Однако в нашем случае ключевым фактором при выборе решения стала почти «нативная» интеграция со Strapi CMS и поддержка различных популярных фреймворков для фронтенда (в нашем случае — ReactJS). Возвращаясь к первоначальной концепции с минимумом кода, стоит сказать, что эта часть решения потребовала привлечения полноценной команды разработки из нескольких человек, ведь создание фронтенда, все же, дело программистов.
Может показаться, что использование классической CMS обеспечивает возможность создания страниц сайта в дизайнере, но нам нужен не набор страниц, а данные референсной модели с возможностью реализации различных сценариев их использования помимо визуализации на сайте.
Технически говоря, статический веб-сайт — это набор html-страниц, доступный для публикации на любом сервере, который умеет «раздать статику». В нашем случае это S3 в Yandex Cloud, но об этом чуть дальше.э
Облачная история, или как получить вычислительные мощности за 5 минут
В целом наша история с реализацией и развитием нового решения похожа на классический и часто канонический пример пользы облачных технологий. Ну, или это, как раз, тот случай, когда использование облачных сервисов избавляет от необходимости согласовывать, заказывать (и ждать!) сервера, настраивать нужные компоненты с привлечением ИТ-команд. Можно просто взять и развернуть нужный набор ресурсов в облаке.
Мы выбрали Yandex Cloud, и на то есть несколько причин, но поскольку эта статья о технологической составляющей, хотелось бы остановиться на конкретных аспектах. Важным для нас стало, что ключевые сервисы Yandex Cloud поддерживают совместимость с AWS-протоколом, а значит, различные плагины и расширения для Strapi/Gatsby могут использовать облако Яндекса, как будто это AWS. Так, в нашем случае настройка S3 для хранения медиаресурсов Strapi потребовала лишь конфигурации плагина (low-code) без необходимости писать что-то свое. Это же явилось большим плюсом при развертывании статической части сайта, где мы воспользовались плагином для GatsbyJS, который умеет публиковать собранные страницы прямо на S3 Yandex Cloud.
Как видно на схеме развертывания, используя единую централизованную систему для управления контентом, мы можем публиковать различные версии сайта на разных целевых серверах. Например, собирать отдельно версию frontend для dev/stage и публиковать на S3 в облаке Яндекса, в то время как prod «живет» и раздаётся с ftp. Так мы получаем возможность создавать «целевые витрины» (сайты) под нужды конкретного клиента. И всё это на одном технологическом стеке!

|
Рис 6. Диаграмма развертывания решения «Витрина референсной модели»
Планы на будущее или «Витрина как сервис»
Созданный технологический задел позволяет развивать текущее решение не просто как веб-сайт с данными референсной модели Rubytech, а делает возможным реализацию более амбициозных бизнес-сценариев. Например, он обеспечивает:
-
Автоматизацию сбора экспертных оценок на постоянной основе с возможностью расширения круга участников оценки за счёт привлечения внешних экспертов и производителей продуктов. Эта часть может быть реализована с использованием сервиса Yandex Forms. Он позволяет гибко настраивать формы для сбора данных и при этом предоставляет возможность интеграции через API (для сбора и анализа результатов). И все это — в парадигме low-code.
-
Развёртывание и настройка решения для различных доменных сущностей с использованием таксономии и объектной модели той предметной области, которая релевантна запросам конкретного заказчика. Причем, решение можно развернуть как в контуре организации (on-premise), так и предоставлять как сервис.
-
Расширение источников данных по продуктам и наполнение каталога Витрины в автоматическом или полуавтоматическом режиме. При этом контроль качества данных, а также экспертная оценка применимости тех или иных решений остаётся за командой аналитики Rubytech.
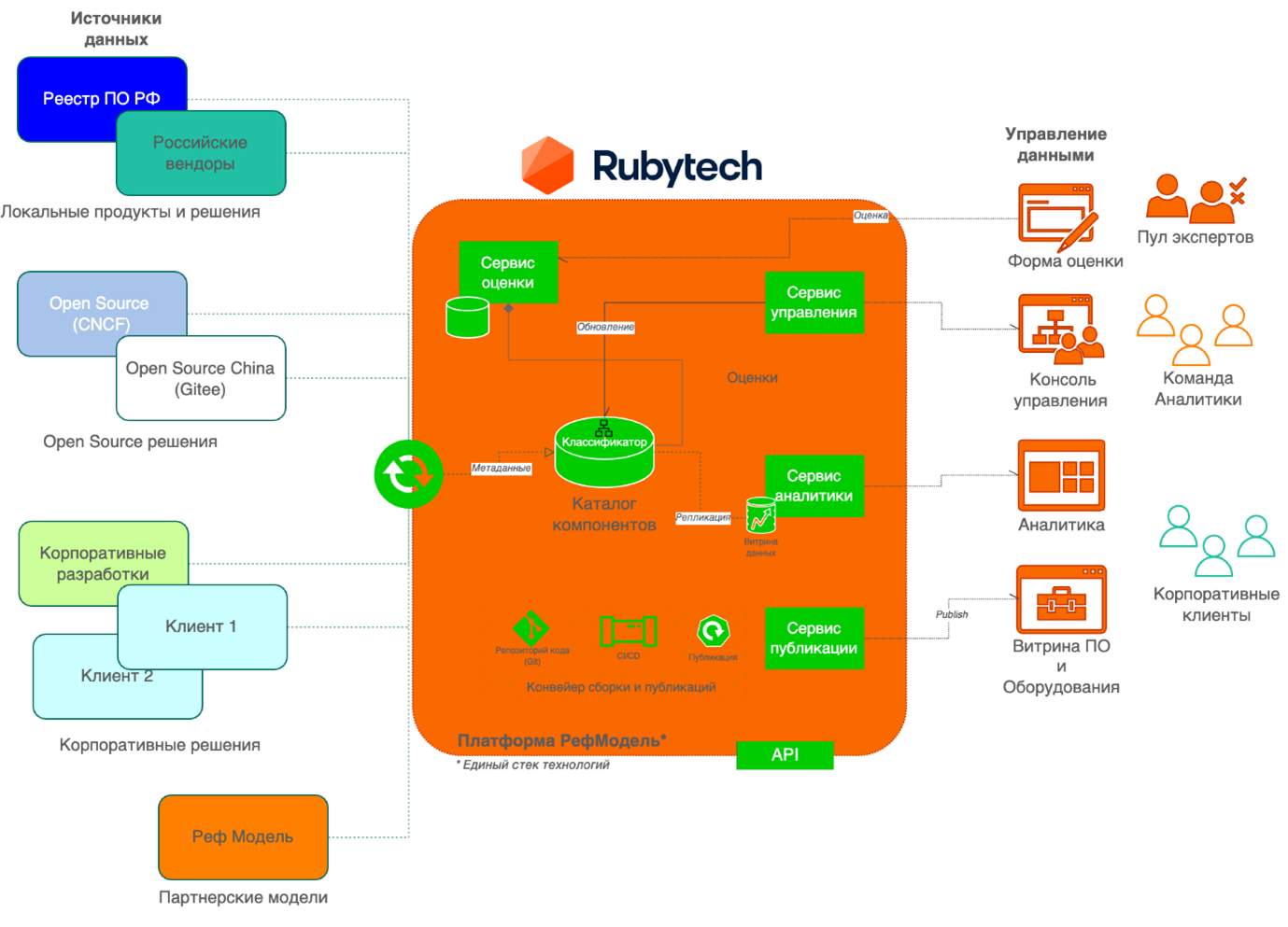
|
Рис 7. Концепция развития Витрины референсной модели Rubytech
Надеюсь, что обзор технологической основы Витрины окажется полезным для вас или, как минимум, вызовет читательское любопытство. Мы всегда открыты к комментариям и обсуждению: коллеги из команды Rubytech готовы поделиться опытом и деталями реализации любого из компонентов решения.
Буду рад вашим вопросам и комментариям!
[1] Референсная модель Rubytech обновляется от двух до четырёх раз в год. В обновлении участвуют эксперты компании, каждый из которых является носителем уникальных знаний о продуктах различных классов. Таким образом, в референсной модели эксперты отражают свои знания о продуктовых предложениях на отечественном рынке. Для Витрины референсной модели используется двухрелизная схема: новые релизы планируются к выходу раз в полгода.
[2] На самом деле небольшие правки стилей на уровне кода для брендирования пользовательского интерфейса нам всё-таки понадобились, но делать это можно было в удобном формате, используя «Темы».
История создания Витрины референсной модели Rubytech — от идеи до реализации
Независимый консультант


